
AI ကို အမြင်အာရုံရအောင် ဘယ်လိုလုပ်မလဲ။ Computer Vision ဆိုတာဘာလဲ။
ကျွန်တော်တို့လို အမြင်အာရုံမျိုး AI မှာလည်းရှိတယ်၊ ဒါပေမယ့် AI ကိုမြင်စေချင်တာ Train ပေးမှသာ ရနိုင်တာမျိုးဖြစ်တယ်။

ကျွန်တော်တို့တွေ ဓါတ်ပုံတစ်ပုံကိုမြင်လိုက်တာနှင့် “ဒါက ဘာဖြစ်တယ်။” ၊ “ဒီလူကတော့ ဘယ်သူ။” ဆိုတာ ခွဲခြားသိနိုင်သလို၊ မျက်စိရှေ့မှာမြင်ရတဲ့ အရာဝတ္ထုတွေကိုလည်း “ဒါကတော့ မော်တော်ကား။” ၊ “ဒါက မီးပွိုင့်။” ၊ “မီးနီနေတယ်။” စသည်ဖြင့် အမြင်နှင့်တန်းပြီးတော့ သိနိုင်ကြတယ်။ ကျွန်တော်တို့လို အမြင်မျိုး AI မှာလည်းရှိတယ်၊ ဒါပေမယ့် AI ကိုမြင်စေချင်တာ Train ပေးလိုက်မှသာ ရနိုင်တာမျိုးဖြစ်တယ်။ AI ရဲ့ အမြင်နှင့်ဆိုင်တဲ့ နည်းပညာကို Computer Vision လို့ခေါ်တယ်။ Computer ရဲ့ Webcam (သို့မဟုတ်) CCTV မှတဆင့် ကမ္ဘာကြီးကို မြင်နိုင်တာမျိုးဖြစ်တယ်။
Computer Vision (CV) ဆိုတာဘာလဲ။
AI Model တစ်ခုကို Image တွေ၊ Video တွေအသုံးပြုပြီး Train ပေးခြင်းဖြစ်တယ်။ AI မှာ Computer Vision ရဖို့အတွက် Machine Learning (ML)၊ Deep Learning (DL) နှင့် Image (သို့မဟုတ်) Video တွေကို Processing လုပ်ပြီးတော့ရလာမယ့် အမြင်မျိုးဖြစ်တယ်။
အလွယ်ပြောမယ်ဆိုရင်တော့
Data + Camera +AI Model ပေါင်းစပ်ခြင်းဟာ AI အတွက် Smart Eyes တစ်စုံဖြစ်တယ်။
AI ရဲ့ Computer Vision နှင့် ဘာတွေလုပ်နိုင်သလဲ။
လူ (သို့မဟုတ်) အရာဝတ္ထုကို
Detect လုပ်တာ
Classify လုပ်တာ
Motion (သို့မဟုတ်) Activity ကို Track လုပ်တာ
AI မှာ Computer Vision ရအောင်လုပ်ဖို့၊ အဓိကလိုအပ်တာတွေက
ရှုဒေါင့်မျိုးစုံ၊ အလင်းအမှောင်မျိုးစုံနှင့် အနေအထားမျိုးစုံ Photo (သို့မဟုတ်) Video တွေ
Photo (သို့မဟုတ်) Video တွေကို Annotation နှင့် Labelling လုပ်ထားတဲ့ Dataset
ရွေးချယ်ထားတဲ့ AI Model
Annotation နှင့် Labeling ကို ဘယ်နေရာကလုပ်မလဲ။
LabelMe (Free)
LabelImg (Free)
LabelStudio (Free)
CVAT (Paid)
LabelBox (Paid)
SuperAnnotate (Paid)
Scale AI (Paid)
Dataloop (Paid)
V7Lab (Paid)
ဘယ် AI Model (သို့မဟုတ်) Platform ကိုရွေးမလဲ။
Models
Convolutional Neural Networks (CNNs)
Vision Transformers (ViTs)
You Only Look Once (YOLO)
Contrastive Language Image Pretraining (CLIP)
Platform
Google (TensorFlow Cloud Service)
Microsoft (CV API - Cloud Service)
Amazon (Rekognition - Cloud Service)
Facebook (PyTorch)
OpenCV (Open-source)
Roboflow
Real-World မှာ Computer Vision ကိုအသုံးပြုနိုင်တဲ့ နေရာတွေ
အလိုလျှောက် မောင်းနှင်တဲ့ကား (Self-Driving Car)
လုပ်ငန်းခွင် အန္တရာယ်ကင်းရှင်းရေး (PPE Detection)
ဓါတ်မှန် အဖြေရှာဖေါ်ထုတ်ခြင်း (Tumors Detection)
လူ အဝင်/အထွက် လုံခြုံရေး (Facial Recognition)
စသည်ဖြင့်
ဥပမာ CV Prototype
ဆိုကြပါစို့ ကားတစ်စင်းကိုမြင်တာနှင့် ဒီကားဟာ ဘာအမျိုးအစားဆိုတာ AI သိနိုင်ဖို့ဆိုရင် သူ့မှာ ကားတွေနှင့်ပတ်သက်တဲ့ အချက်အလက်တွေရှိဖို့လိုတယ်။ အခု Prototype လေးကလည်း Toy Car လေးတွေကို Camera မှာပြလိုက်တာနှင့် ကားအမျိုးအစား ၆မျိုးထဲက ဘာကားအမျိုးအစားလဲဆိုတာ Classify လုပ်ပေးမှာဖြစ်တယ်။ အရင်ဆုံးဒီ Prototype အတွက် Toy Car ကားအမျိုးအစား ၆ မျိုးရဲ့ ရှုဒေါင့်မျိုးစုံ၊ အလင်းအမှောင်မျိုးစုံ၊ ဓါတ်ပုံစုစုပေါင်းပုံ ၉၀ ကို Phone Camera နှင့် ရိုက်ပြီးတော့ Data စတင်စုဆောင်းတယ်။ (ပိုတိကျချင်ရင်တော့ ပုံပေါင်း ၅၀၀ ကျော်လောက်စုဆောင်းသင့်တယ်။) ပုံတွေအကုန်လုံးကို yolo\toy_cars folder အောက်မှာထားလိုက်တယ်။
ဓါတ်ပုံတွေရဲ့ Extension က .HEIC ဖြစ်နေလို့ .JPEG ပြောင်းတယ်၊ Folder ထဲက .HEIC File တွေကိုတော့ ဖျက်ပစ်လိုက်တယ်။
Annotation နှင့် Labelling အတွက် Label Studio နှင့် အသုံးပြုထားတယ်။ Label Studio က Web Application ဖြစ်တာကြောင့် localhost မှာ Run တယ်။ Label Studio မသုံးခင် အရင်ဆုံးသူ့ထဲမှာ Local Account Create လုပ်ပေးဖို့လိုတယ်။ Account ရပြီဆိုရင်တော့ Login ဝင်လိုက်ပြီး Project တစ်ခု Create လုပ်ရတယ်။
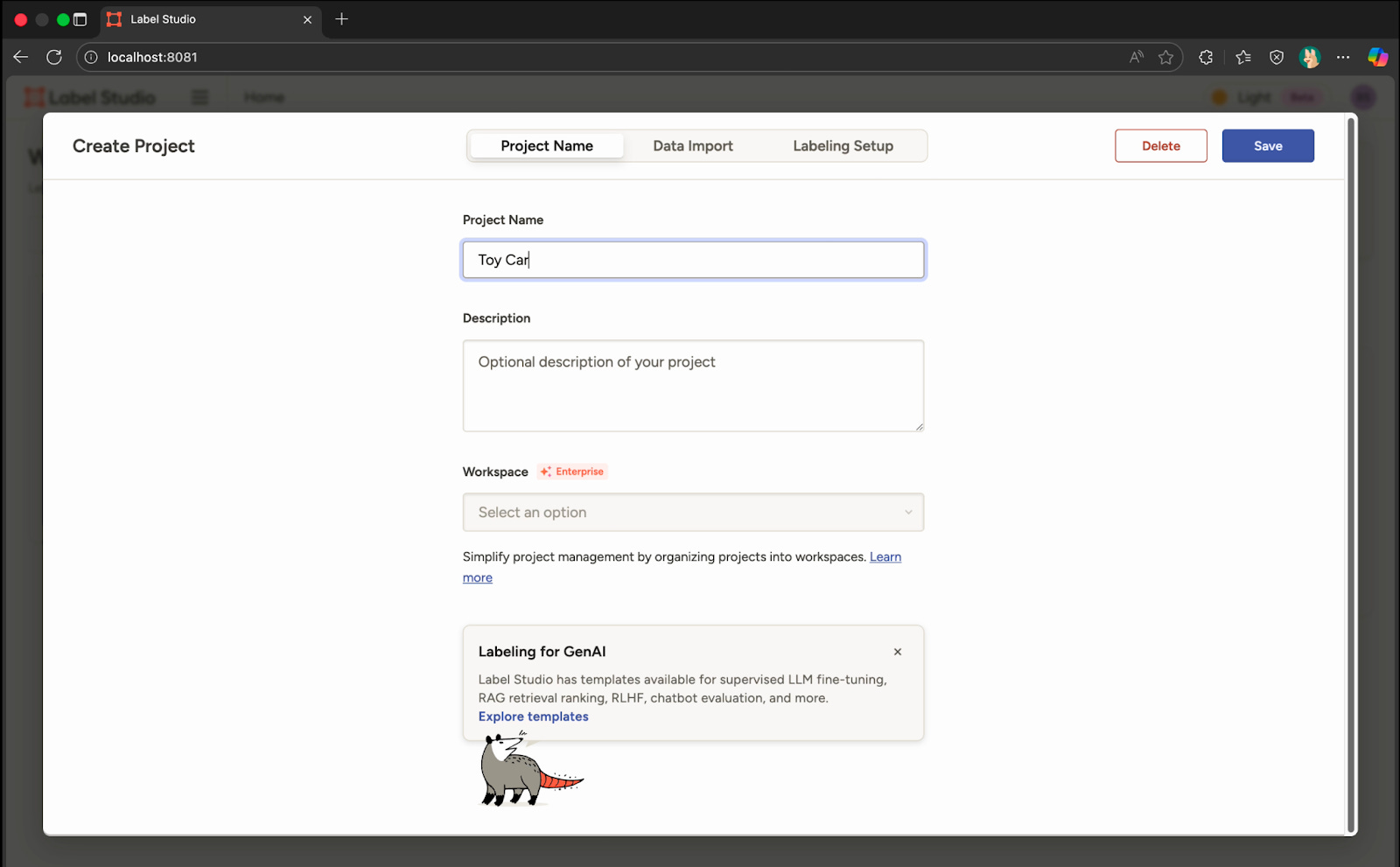
Project Name ကို Toy Car လို့ပေးပြီးတော့ Data Import ကို ဆက်သွားတယ်။
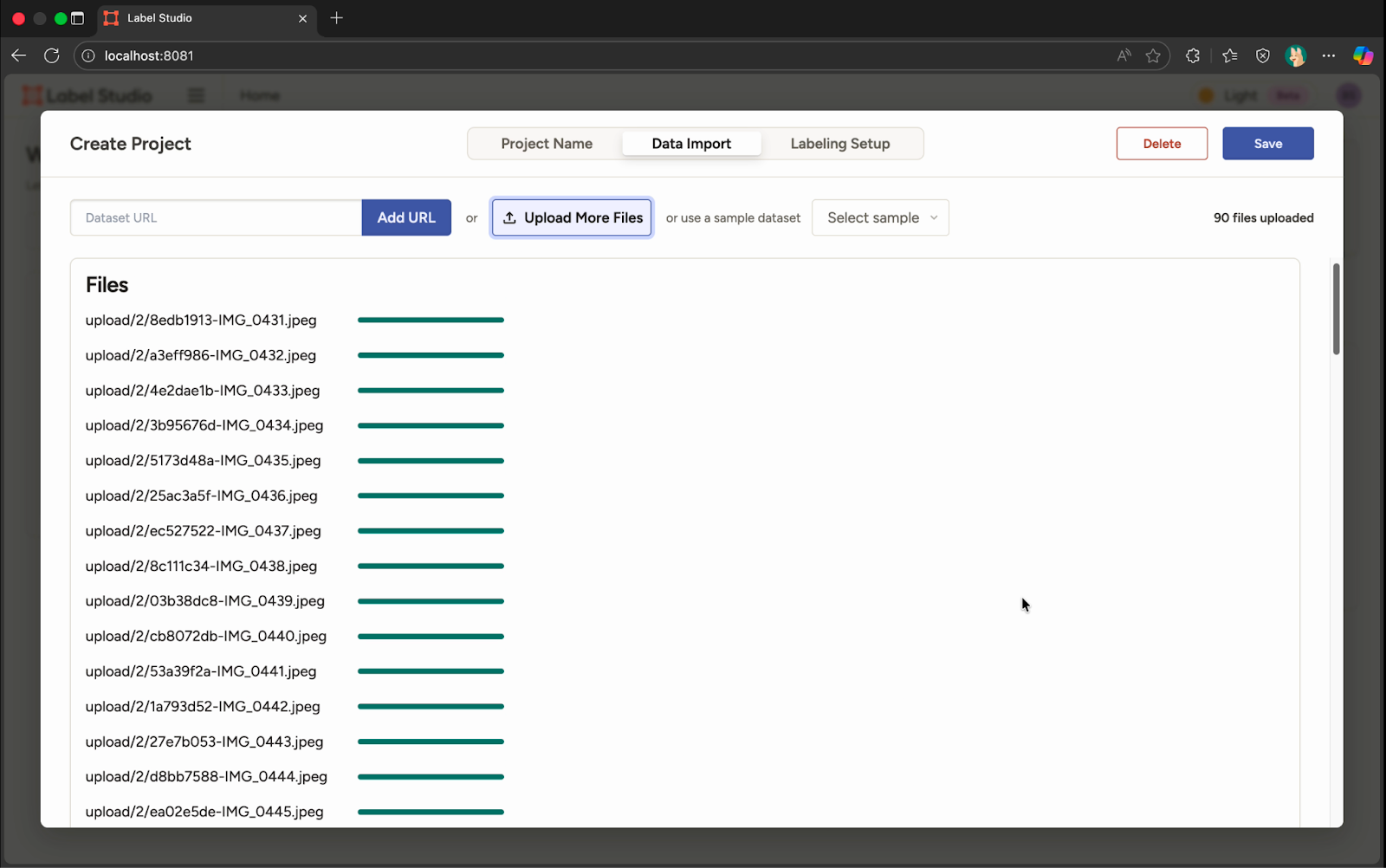
ပြီးတော့ Upload File နှင့် အသုံးပြုမယ့် ဓါတ်ပုံတွေကို ထည့်ပေးလိုက်တယ်။
Label Setup မှာ အသုံးပြုမယ့် Label ပုံစံကိုရွေးပေးရမယ်။ CV အတွက်လား၊ LLM အတွက်လား၊ စသည်ဖြင့် Content အမျိုးအစားနှင့်ဆိုင်တဲ့ Label အမျိုးအစားကိုရွေးပေးရမှာဖြစ်တယ်။ အခုကျွန်တော့် Prototype က CV အတွက်ဖြစ်တာကြောင့်၊ Computer Vision (CV) ကိုရွေးလိုက်တယ်။ နောက်ထပ်ရွေးရမှာက ဘာကို Vision လုပ်မှာလဲဆိုတဲ့ အမျိုးအစားကိုထပ်ရွေးရမယ်။ စာသားတွေကို လုပ်မှာလား၊ အစိတ်အပိုင်းတစ်ခုကို လုပ်မှာလား၊ Tracking လုပ်မှာလား စသည်ဖြင့်ရွေးရမယ်။ ကျွန်တော့် Prototype မှာတော့ Image ထဲမှာမြင်ရတဲ့ Object တွေအတွက်လုပ်ချင်လို့ Object Detection with Bounding Boxes ကို ရွေးလိုက်တယ်။ နောက်ဆုံးမှာ Labeling Interface ထဲကို ပုံမှာမြင်ရတဲ့အတိုင်း ရောက်သွားတယ်။
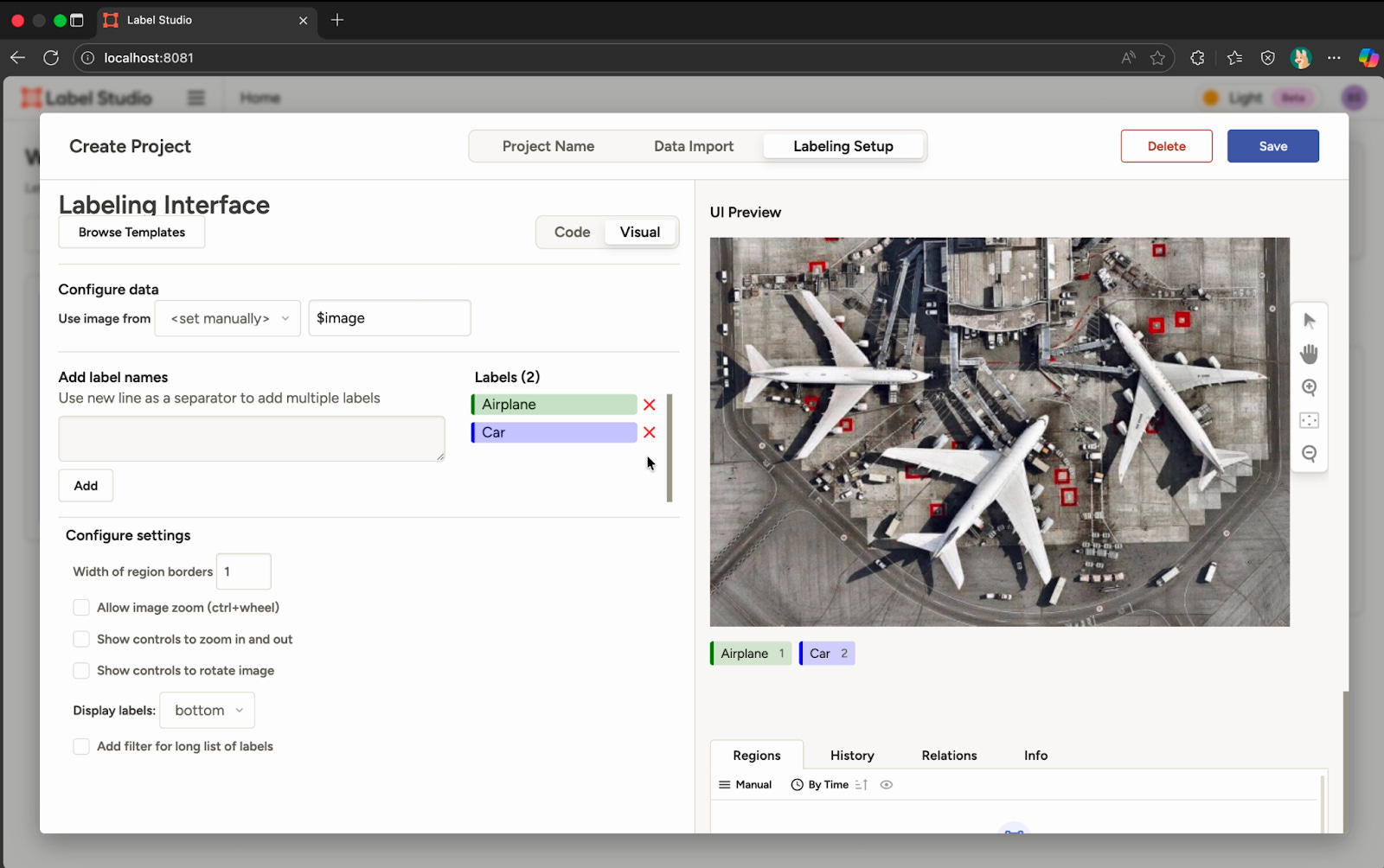
Code နှင့် Visual View နှစ်ခုတွေ့ရမယ်၊ နမူနာ Label နှစ်ခုပြထားတယ်၊ နမူနာပြထားတဲ့ Label နှစ်ခုကို ဖျက်ပြီးတော့၊ Prototype အတွက် သတ်မှတ်ချင်တဲ့ Label ၆ မျိုးကို ထည့်လိုက်တယ်။
mercedes benz g63
mini cooper
dc comics
forklift
70 camaro rs
gmc hummer
Label တစ်ခုချင်းစီကို မတူညီတဲ့အရောင် ၆ မျိုးနှင့်ပြပေးထားတာတွေ့ရမယ်၊ Project ကို Save လုပ်ပြီးရင် အောက်ပါအတိုင်းတွေ့ရမယ်။
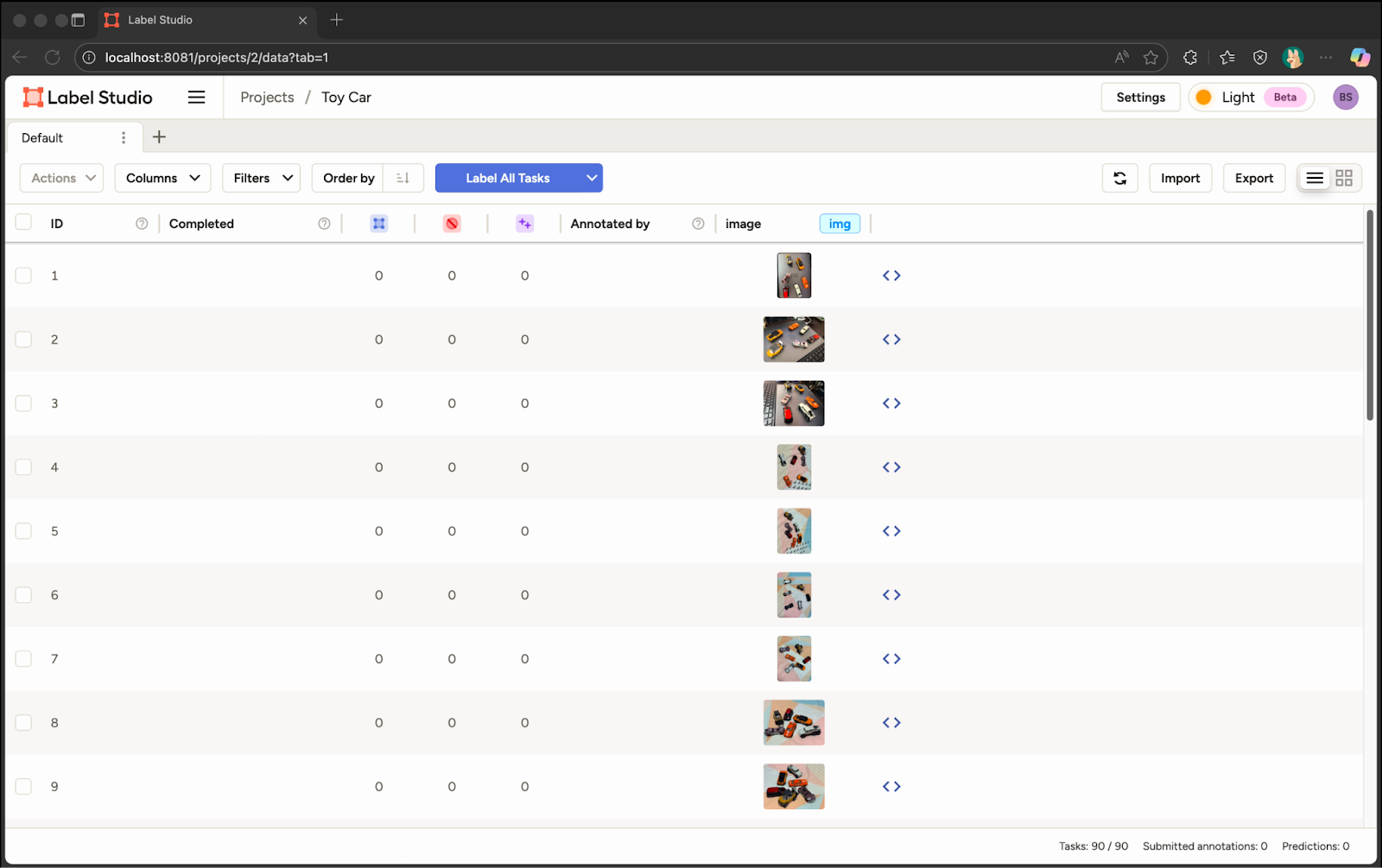
Image တွေမှာ Label တွေထည့်ဖို့ အဆင်သင့်ဖြစ်နေပြီမို့လို့ ပထမဆုံးပုံကို Click နှိပ်ပြီး Label စတင်ထည့်တော့မယ်။
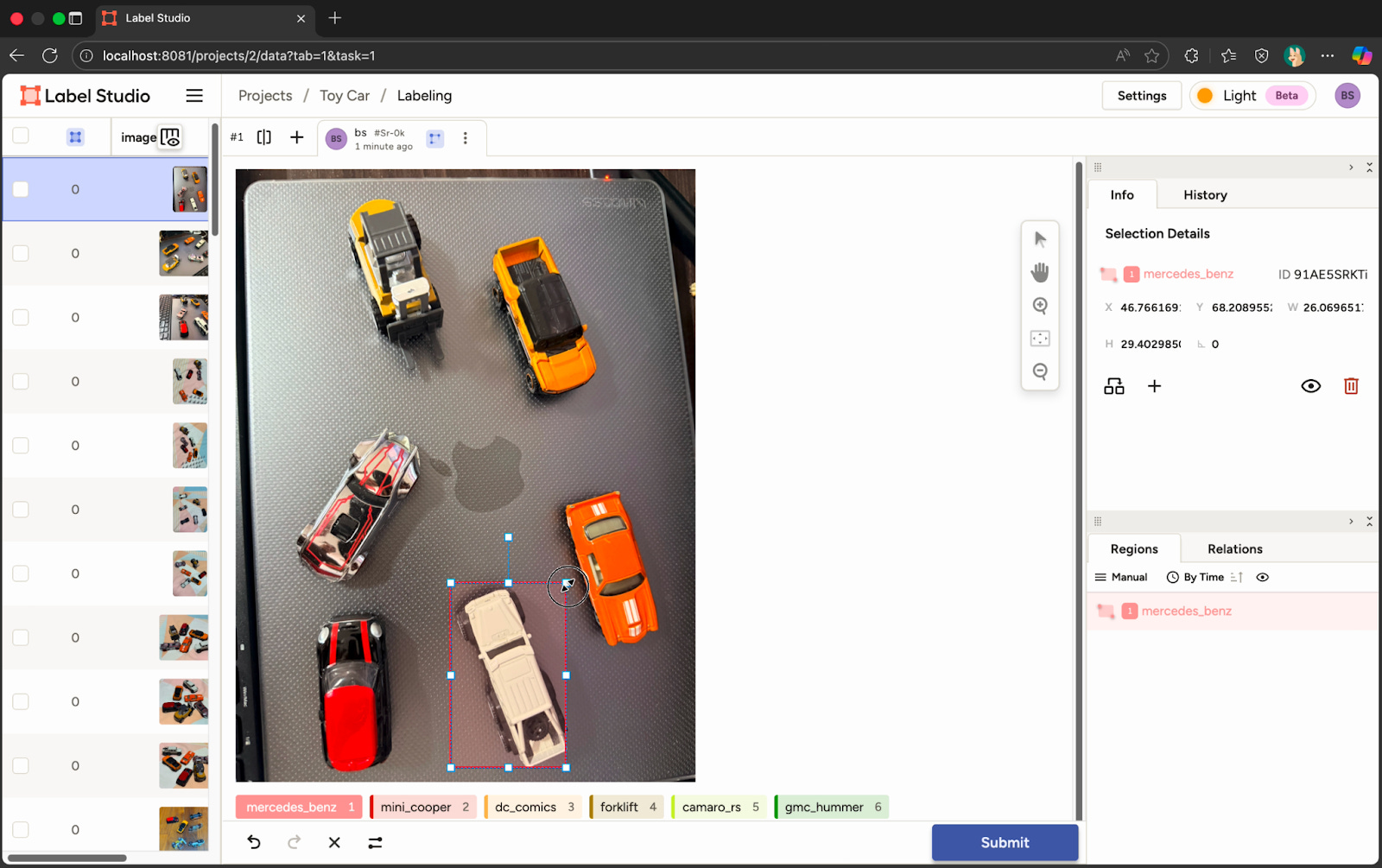
ပုံရဲ့အောက်မှာမြင်ရတဲ့ Label ၆ မျိုးကို တစ်ခုချင်းစီရွေးပြီး သက်ဆိုင်ရာပုံပေါ်မှာ အပေါ်မှာပြထားသည့်အတိုင်း Label တွေထည့်ပေးရမှာဖြစ်တယ်။ Object နှင့် အတိအကျဖြစ်အောင် သေချာညှိပေးရမယ်၊ တစ်ခုပြီးရင် အချုံအချဲ့လုပ်တဲ့ လေးထောင့်အတုံးလေးတွေ ပျောက်အောင်သေချာ Click နှိပ်ပြီးမှ၊ နောက် Label တစ်ခုကိုရွေးပြီး နောက်ထပ် Object အတွက် Label သတ်မှတ်ပေးရတယ်။ ဒီလိုနှင့် တစ်ခုချင်းစီ ဓါတ်ပုံတွေအကုန်လုံးအတွက် Label တွေကို အချိန်ပေး၊ စိတ်ရှည်ရှည်နှင့် Label တွေထည့်ပေးရပါတယ်။
ဓါတ်ပုံတွေအတွက် Label တွေထည့်ပြီးပြီဆိုရင်တော့၊ Dataset ကို Export လုပ်လို့ရပါပြီ။
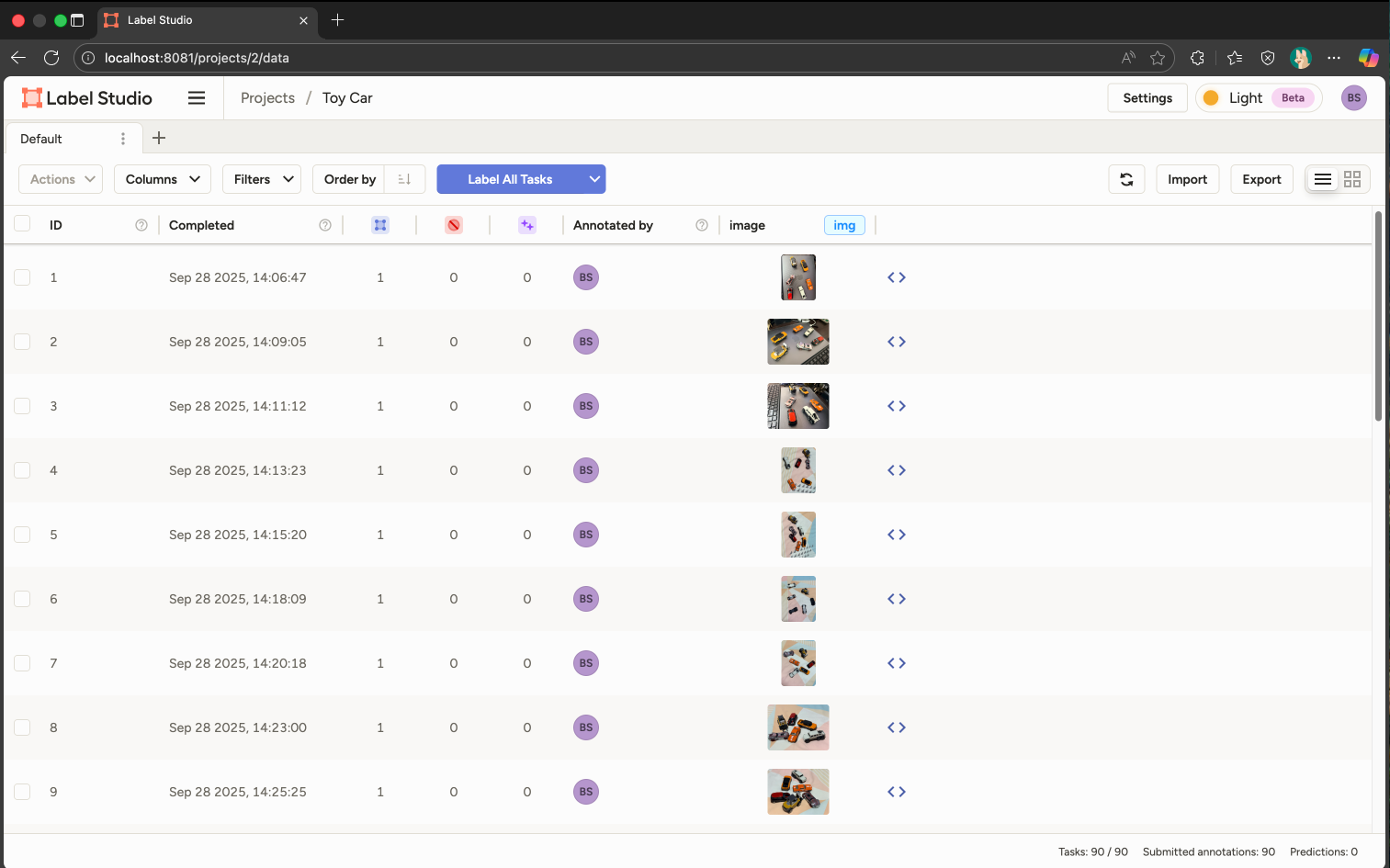
Export လုပ်တဲ့အခါ CV Model ထဲမှာ အသုံးပြုမယ့် Dataset အမျိုးအစားပေါ်မှာမူတည်ပြီး လုပ်ရမှာဖြစ်ပါတယ်။ ကျွန်တော့် Prototype ကတော့ YOLO Model အတွက်ဆိုတော့ YOLO with Images ကိုရွေးချယ်ပြီး Export လုပ်လိုက်ပါတယ်။ Export ပြီးရင် Zip ဖိုင်ထဲမှာ အခုလို images နှင့် labels Folder နှစ်ခုပါတဲ့ Dataset တစ်ခုရလာမှာဖြစ်ပါတယ်။
Dataset ရပြီဆိုရင် သူ့အတွက်နောက်ထပ် အရေးကြီးတာတစ်ခု လုပ်ပေးဖို့လိုတယ်။
Dataset ကို (Train ၊ Valid ၊ Test) ၃မျိုး Splitting လုပ်ခြင်း
Train မယ့် Data တွေကြောင့် AI Model Overfitting မဖြစ်အောင် Dataset ကို Splitting လုပ်ပေးရတာဖြစ်တယ်၊ နောက်ပြီး Common Practice တစ်ခုလည်းဖြစ်တယ်။ Overfitting ဖြစ်တယ်ဆိုတာ Machine Learning မှာ Train ခဲ့တဲ့ Data တွေနှင့်အသားကျသွားပြီး၊ Data အသစ်တွေဆို မသိတော့တာမျိုးဖြစ်တယ်။ ဥပမာ Showroom ထဲမှာရပ်ထားတဲ့ကားကို ခွဲခြားသိနိုင်ပြီး၊ အခြားနေရာကရပ်ထားတဲ့ကားကို မခွဲခြားနိုင်တော့တာမျိုးဖြစ်တယ်။ Splitting လုပ်ခြင်းက AI ကို ဘက်လိုက်ပြီး အဖြေထုတ်တာမျိုးလည်းမဖြစ်ဖို့ အထောက်အပံ့ဖြစ်တယ်၊ Valid Dataset ကြောင့်လည်း အချိန်တိုအတွင်း မှန်ကန်တဲ့အဖြေကိုရှာပေးနိုင်တယ်။ ဒီအချက်တွေကြောင့် Splitting လုပ်ဖို့လိုတယ်။ ကျွန်တော့်ရဲ့ Prototype အတွက် Dataset ကို Splitting လုပ်ဖို့ Project ထဲမှာ Python ဖိုင်တစ်ဖိုင်ပါတယ်။
Dataset ကို toy_car လို့နာမည်ပေးပြီး datasets Folder ထဲကို ထည့်ထားတယ်။
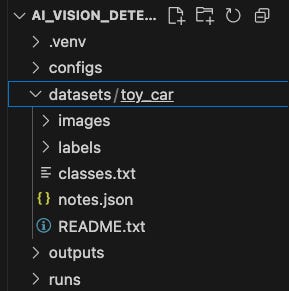
Project ကို Visual Studio Code ဖွင့်ပြီးတော့ Terminal ထဲမှာ အရင်ဆုံး Python Program Run ဖို့ Virtual Environment တစ်ခုဖန်တီးတယ်၊ .venv ကို Activate လုပ်တယ်၊ ပြီးတော့ pip နှင့်လိုအပ်တဲ့ Library ကို install လုပ်လိုက်တယ်။
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Dataset ကို Splitting လုပ်လိုက်တယ်
python split_dataset.py
images နှင့် labels တွေအောက်မှာ train ၊ val နှင့် test ၃ခု ပေါ်လာပြီးတော့ toy_car ထဲကဖိုင်တွေကို ၃ နေရာခွဲထည့်လိုက်တာဖြစ်တယ်။ ပြီးရင် Dataset Folder Structure ကို Verify လုပ်ကြည့်မယ်။
python tools/verify_dataset.py datasets/toy_car
Dataset ကအဆင်ပြေတယ် ဒါကြောင့် YOLO ကို စတင် Train လိုက်ပြီ။
python train.py --data configs/cv_dataset.yaml --epochs 50 --img 640
epoch ဆိုတာ Dataset တစ်စုံလုံး AI Model ထဲကို လုံးလုံးလျှားလျှား ဖြတ်သန်းသွားသည့်ဖြစ်စဉ်တစ်ခု ဖြစ်ပါတယ်။ Dataset ရဲ့ Size ပေါ်မူတည်ပြီး epoch ကို ဘယ်နှစ်ကြိမ်သတ်မှတ်မလဲ ဆိုတာကလည်း အခရာကျပါတယ်။ Overfitting နှင့် Underfitting ဖြစ်တာတွေက epoch အကြိမ်အရေအတွက် သတ်မှတ်တာနှင့် တိုက်ရိုက်ပတ်သက်ပါတယ်။ အနည်းဆုံးကတော့ epoch 50 သတ်မှတ်လေ့ရှိကြပြီး၊ အများဆုံးကတော့ Dataset ပေါ်မူတည်ပြီး 500 ကျော်ထိ သတ်မှတ်လေ့ရှိပါတယ်။ Train လို့ပြီးသွားရင်တော့ Laptop ရဲ့ Webcam နှင့် Testing လုပ်ကြည့်ပါတယ်။
python detect.py --source 0
နဂုံးချုပ်
AI Model တွေကို Train တဲ့အခါမှာ အခြေခံသဘောတရားက တူပေမယ့် Concept နှင့် Approach ကတော့ Model Architecture ၊ အသုံးပြုမယ့် Dataset နှင့် ရည်ရွယ်ချက် စသည်တို့ပေါ်မှာမူတည်ပြီး ကွဲပြားပါတယ်။
Source Code: AI Vision Detector